basic user registration form and CSRF Section 11, Lecture 41
デフォルトではgetリクエストになる。
none設定をする
1. localhost/registerにアクセスする
2. GETリクエストなのでreturnでページを表示する
3. 次にuserがフォームを入力してsubmitを推した場合はPOSTなので
ifぶんのPOSTを発動する。
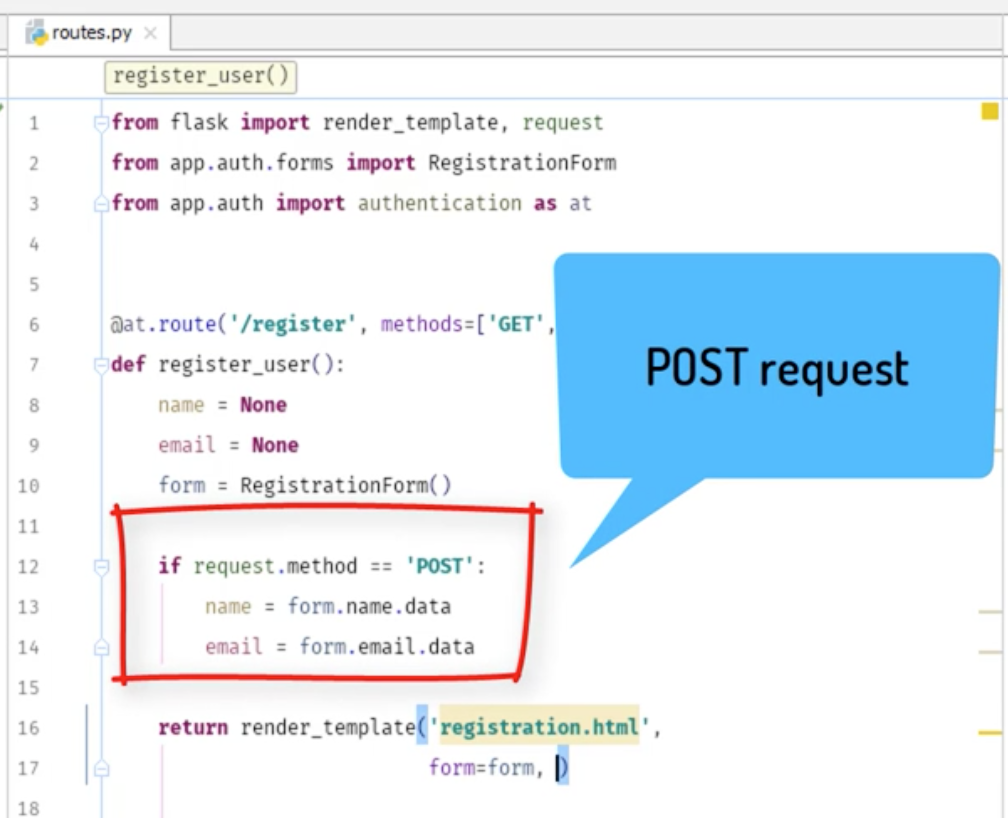
4. returnにデータを保存する。name=name, email=emailとして
5. {% if (name) and (email) %}とする事で文字が入っている場合の処理をする。
 実際に実行するとこうなる
実際に実行するとこうなる

Form作製の場合のセキュリティーの作り方
これをする事でハッキングを防ぐことができる。

registlation.htmlで {{form.hidden_tag()}} を設定する事で
FLaskを暗号化することができる。
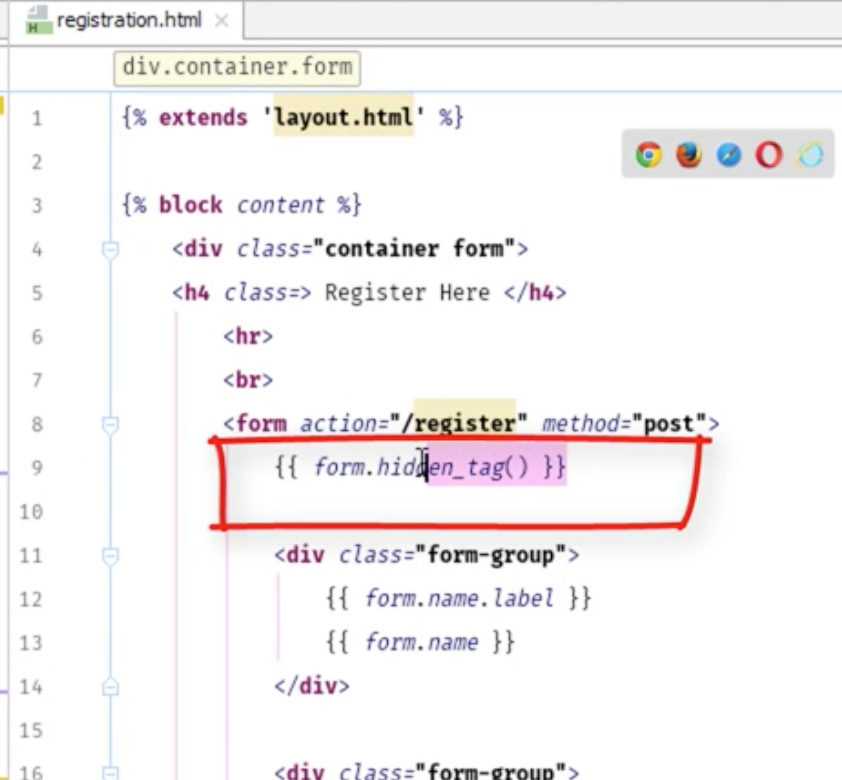 実際に暗号化したときはトークンとして出てくる。
実際に暗号化したときはトークンとして出てくる。

creating users in the database Section 11, Lecture 43
models.pyを作る
ユーザー管理用のデータベースを作る。
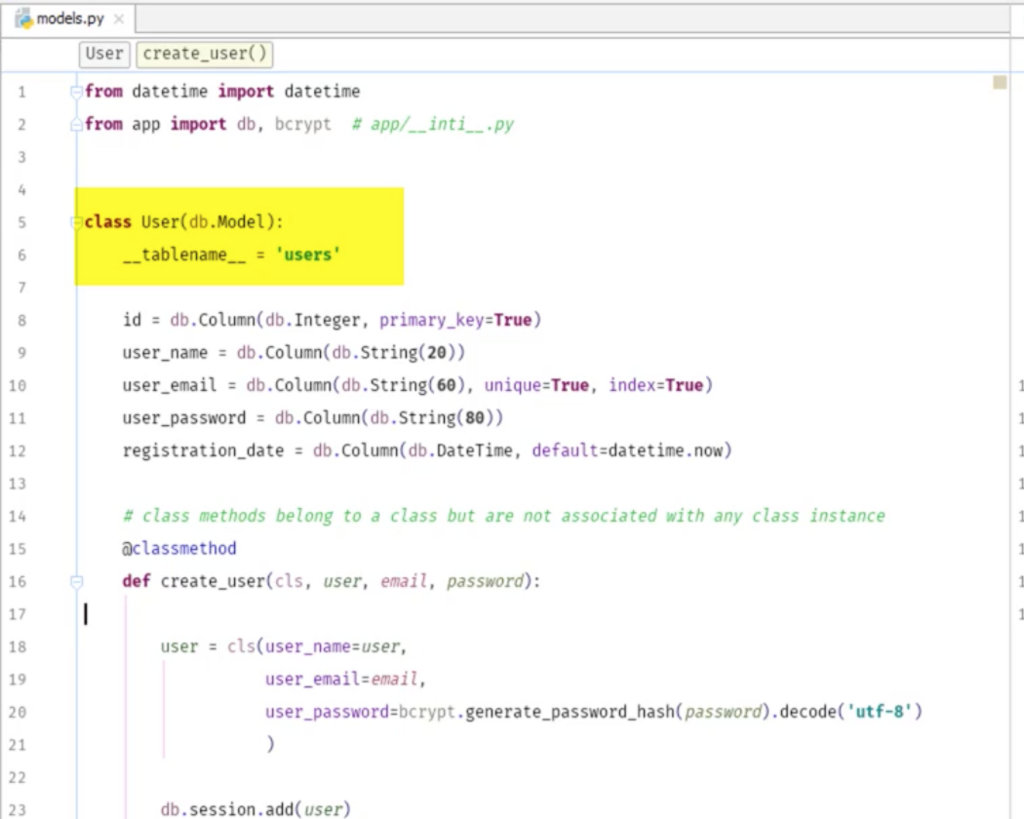
インスタンスではなくクラスを作る。
functionとして@classmethodを作る。
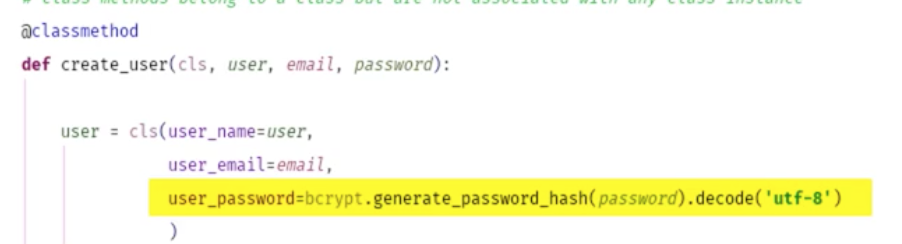
selfではなく、クラスなのでclsを置く。また、パスワードはハッシュ化する。
python3なのでutf-8の設定もする。
【通常の場合】
インスタンス化→インスタンス.関数名で使うことができる。
class ClassTest:
def this_is_instance_method(self):
print("これはインスタンスメソッドです。")
instance1 = ClassTest()
instance1.this_is_instance_method()
【クラスメソッドの場合】
インスタンス化不要→クラスメソッド.関数名で使うことができる。
classの下に@staticmethodをつけるだけでインスタンス化不要なので楽である。
class ClassTest:
@staticmethod
def this_is_static_method():
print("これはスタティックメソッドです。")
ClassTest.this_is_static_method()
データベースに保存する。
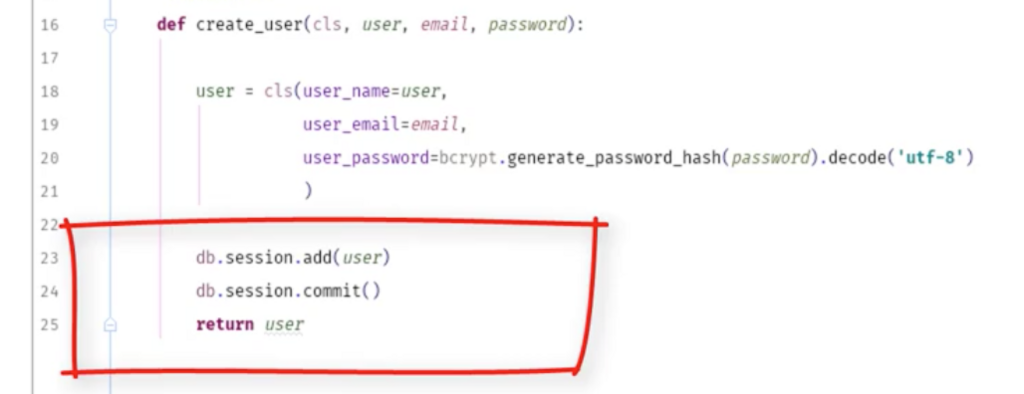
run.pyに以下の設定をする事ですでにユーザーが存在するかを確認する。

追加でハッシュ化することでハッキングされてもパスワードを分からないようにする。

bcryptの使い方の説明 flask login and password hashing using bcrypt Section 11, Lecture 42
bcryptの使い方の説明
最初にやる事は同じ

実際にpasswordをハッシュ化ってどんな風にやっているのか? Bcryptの'generate_password_hash'に注目する!これでハッシュ化する。
$ pip install flask_login $ pip install flask_bcrypt >>> from flask_bcrypt import Bcrypt >>> bcrypt = Bcrypt() >>> dir(bcrypt) ['__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__', '_log_rounds', 'check_password_hash', 'generate_password_hash', 'init_app'] >>> password = 'yamada' >>> hashed_password = bcrypt.generate_password_hash(password) >>> hashed_password b'$2b$12$8fz7XhXOSp7QHqoaFZNRWOwLZXWqgWkXfoHWyJwNrRCiRdlWC6FPy'
次に check_password_hash でパスワードがマッチするかを確認する。
hashed_passwordと設定したpasswordが一致すればTrueになる
>>> bcrypt.check_password_hash(hashed_password, password) True
a simple form Section 11, Lecture 40
Catalog Packageと同じ流れやる
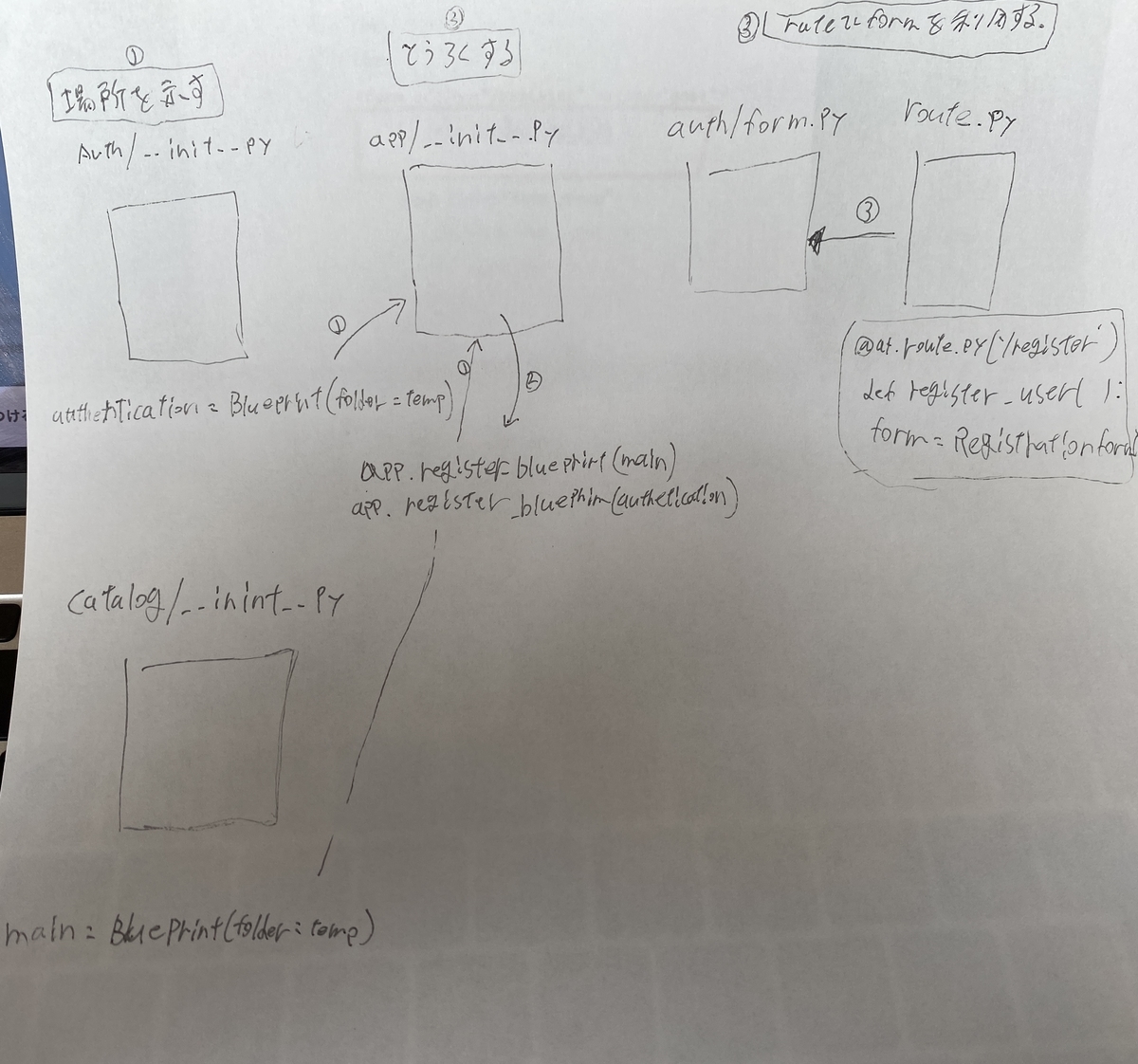 1. init.py, blueprint
1. init.py, blueprint
2. app/init.pyに登録する
3. form.pyを作成する
4. route.pyを作成する(functionなど定義する)
5. htmlを準備する
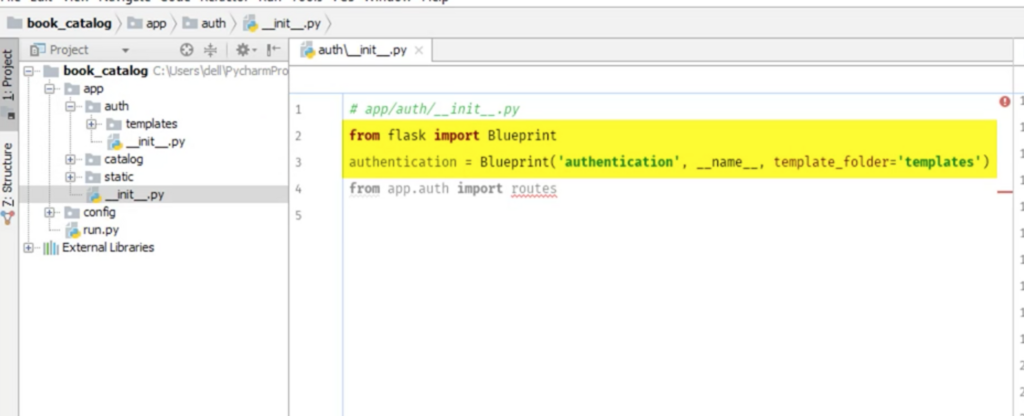
Authフォルダーにinit.pyを作る
BluePrint をimportする。
blueprintのインスタンスを作る。
そして、route.pyをimportする。
app/init.pyにカタログの時とお同じようにAuth appを登録(register)する。
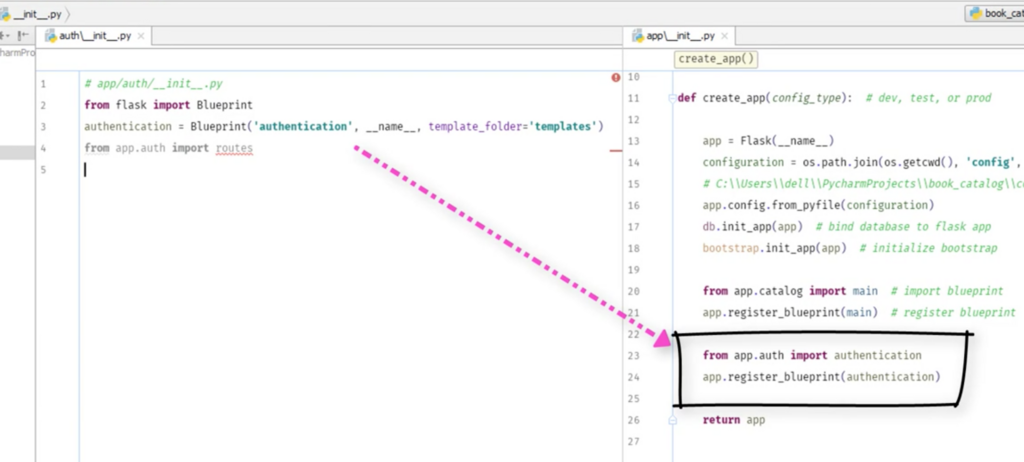
ここからはフォームを作る。form.pyとroutes.pyを作る。
flaskのwtfを利用する。

auth/form.pyを作成する。

auth/route.pyを作成する。
route.pyでform.pyをimportする
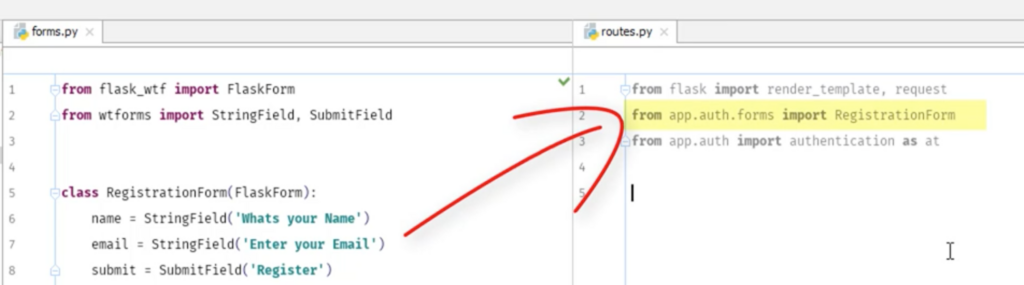
次にroute.pyを作る
formというインスタンスをつくる
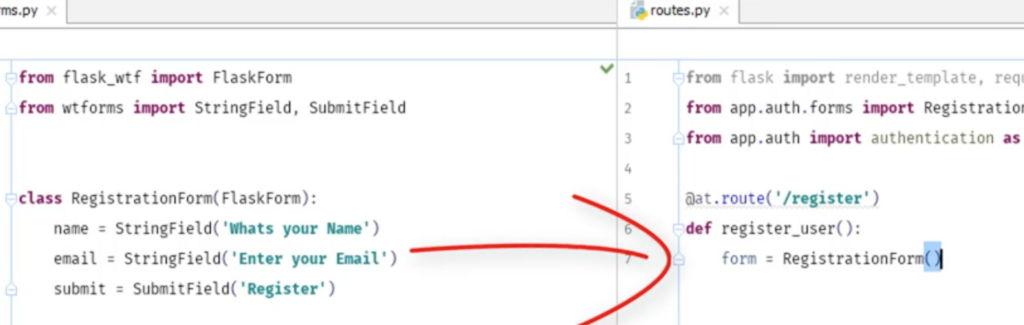
formをhtmlに渡して表示させたいので、form=formにする
 完成版が以下の通りだ。
完成版が以下の通りだ。
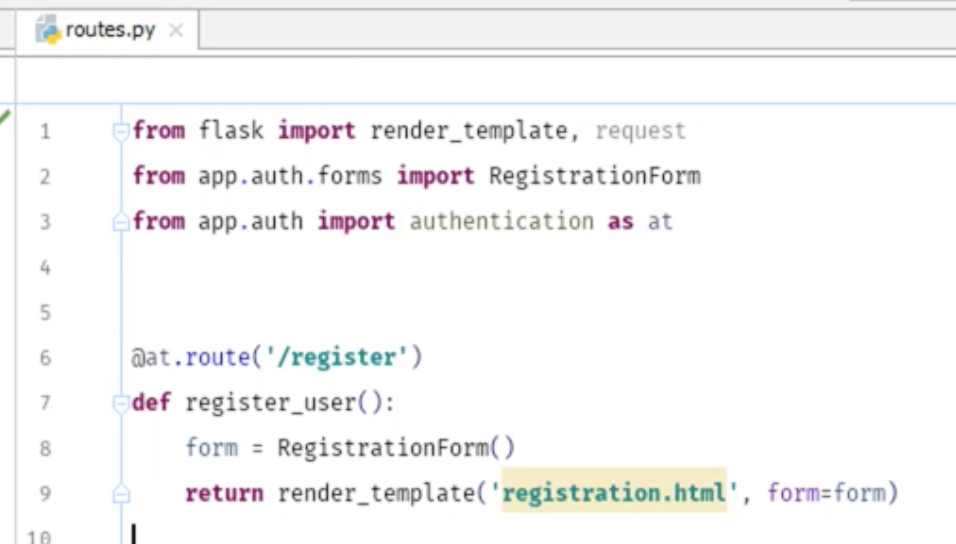
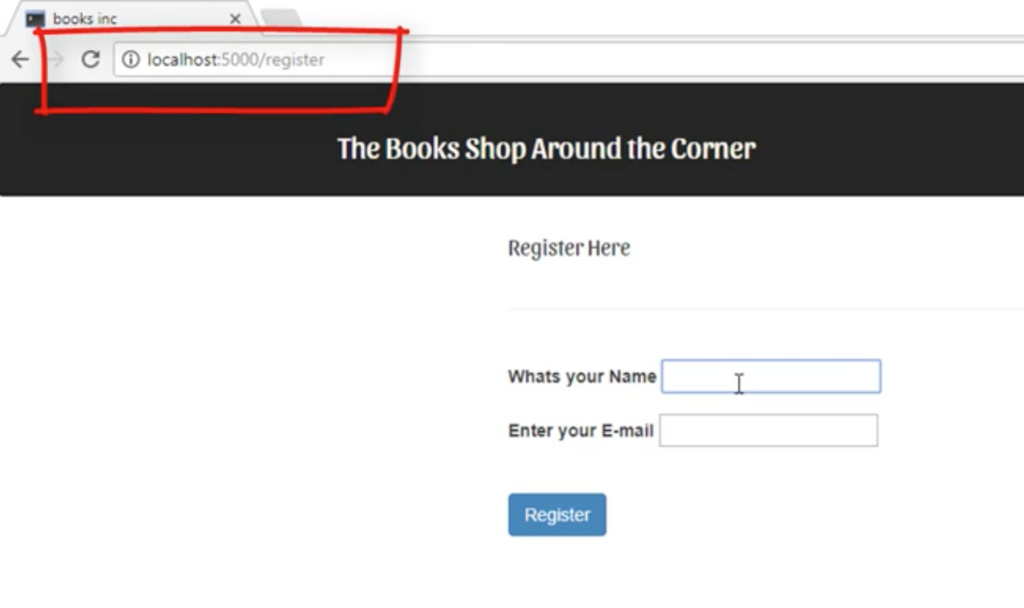
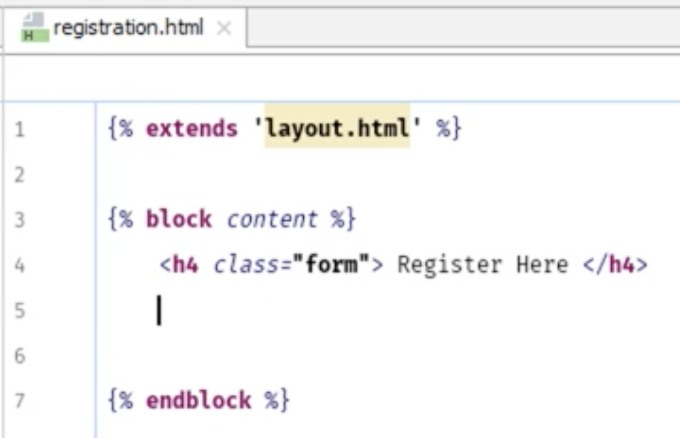
次にregister.htmlを作成する。 最初にやる事は同じこと
{% extends 'layout.html' %}
{% block content %}
{% endblock %}
Scaling Applications 最低限で動かす
最低限でblueprintを使いこなす。
上から順に書きなぐる
Flaskは主にこの3つで構成される。
appフォルダー
configフォルダー
run.py
├── app │ ├── __init__.py │ ├── __pycache__ │ │ └── __init__.cpython-36.pyc │ ├── auth │ │ ├── __init__.py │ │ └── __pycache__ │ │ └── __init__.cpython-36.pyc │ └── catalog │ ├── __init__.py │ ├── __pycache__ │ │ ├── __init__.cpython-36.pyc │ │ └── routes.cpython-36.pyc │ ├── models.py │ ├── routes.py │ └── templates ├── config │ ├── dev.py │ ├── prod.py │ └── test.py └── run.py
#run.py
from app import create_app
if __name__ == '__main__':
flask_app = create_app('dev')
# with flask_app.app_context():
# db.create_all()
flask_app.run()
app/ init.pyの役割
主な役割は2つあります
①pythonスクリプトがあるディレクトリを表す役割
②必要なモジュールをimportするなどの初期化処理を記載し,初期化の役割を担う役目があります。
つまり、異なるディレクトリのファイルをインポートする際にその役割を発揮する。いちいちimportしなくてもいい。
Blueprint を登録する。
app.register_blueprint(main)
# app/__init__.py
import os
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
db = SQLAlchemy()
def create_app(config_type): # dev, test, or prod
app = Flask(__name__)
configuration = os.path.join(os.getcwd(), 'config', config_type + '.py')
# C:\\Users\\dell\\PycharmProjects\\book_catalog\\config\\dev.py
app.config.from_pyfile(configuration)
db.init_app(app) # initialize database
from app.catalog import main
app.register_blueprint(main)
return app
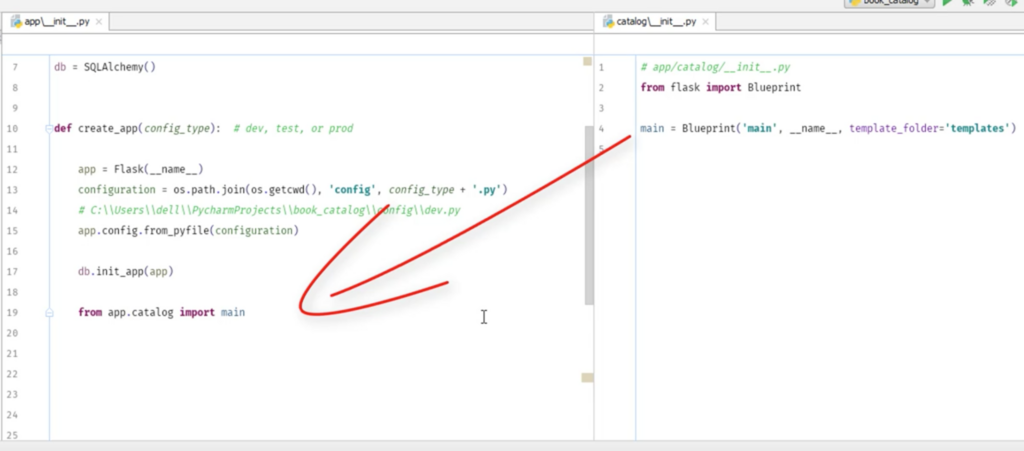
# app/catalog/__init__.py
from flask import Blueprint
main = Blueprint('main', __name__, template_folder='templates')
from app.catalog import routes
catalog/init.pyでmainを作って、app/init.pyにmainを送る
'main', →名前
name, →引数。フォルダー名を指定する。
template_folder='templates'→引数。フォルダーとパスを指定する。
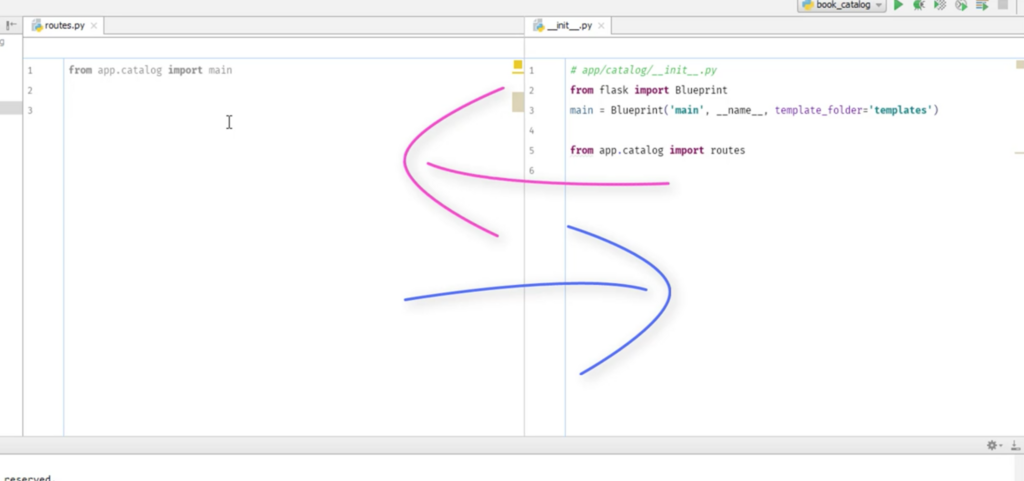
#catalog/routes.py
from app.catalog import main
@main.route('/')
def hello():
return 'hello worlld'
一連の流れを整理する必要がある。
run.pyによってdef create_appが動き出す。
お大河にimportmし合うので順番間違えるとエラーが出る。サーキュレーション問題である。
1. run.pyでflask_app.run()。ここでdev,prodtestを選ぶ
2.init.pyでcreate_app関数でconfig収集、DB接続、app.register_blueprint(main)blueプリント登録
3.routes.pyで@main.route('/')で表示設定
app/init.pyがmainをよび出す。
mainは# app/catalog/init.pyにある。
app/catalog/init.pyが発動する。
route.pyを呼び出す。
@main.route('/')のhello worldが# app/catalog/init.pyに送られる。
app/catalog/init.pyのmainが完成する。
その後で# app/init.pyのmainが完成する。
【Scrapy】Selenium
◆メソッド
・find_element_by_xpath(xpath)
◆使用形態
・driver.find_element_by_xpath("//div/div/td[1]")
◆備考
・引数に取得したい要素のxpathを指定することで要素を取得できる
・引数で指定する属性値やインナーテキストなどの「値」はシングルクォーテーションで囲われる必要がある
◆関連項目
・id属性から要素を取得する
・name属性から要素を取得する
While文をマスターしたい。
pythonのwhile文のbreakを使ったループの中断条件の作り方 | HEADBOOST
exceptをマスターしたい。
【Scrapy】Selenium
今回の章
セクション13:Scrapy with Selenium
今回の目的
各書籍のURLを取得」→「順に詳細ページをスクレイピング」→「次のページへ移動」→「各書籍のURLを取得」→「詳細ページをスクレイピング」というようなイメージでクローラーを動かせば良い。
独自プログラムとしてyahoonewsもやってみた。
>>> driver = webdriver.Chrome('/Users/macbookproy/dev/venv_20201101/20201121/driver/chromedriver')
>>> driver.get( "http://www.yahoo.co.jp" )
>>> driver.title
①attribute = 属性
②method = メソッド
from selenium import webdriver
#ChromeDriverのパスを引数に指定しChromeを起動
driver = webdriver.Chrome("D:\chromedriver")
#指定したURLに遷移
driver.get("https://www.yahoo.co.jp")
#カレントページのソースコードを取得して表示
print(driver.page_source)
seleniumは色々なメソッドが用意されている。
今回はpage_source
◆メソッド ・page_source ◆使用形態 ・driver.page_source ◆備考 ・カレントページのソースコードを取得
>>> driver = webdriver.Chrome('/Users/macbookproy/dev/venv_20201101/20201121/driver/chromedriver')
>>> driver.get( "https://news.yahoo.co.jp" )
>>> from scrapy.selector import Selector
>>> sel = Selector(text=driver.page_source)
>>> sel.xpath('//*[@id="contentsWrap"]/section[1]/div/div/div/ul/li/a/text()').extract()
['NY株、一時3万ドル超える', '閉会後に安倍氏聴取へ調整', '町議が性被害訴え 議会に殺気', 'ドコモ元社員男性 セクハラ訴え', '帰省の代わりに年賀状 受注増', 'ナイキCM批判 背景の日本人観', '芸能記者 注目した渡部の言葉', '渡部会見 100分間の集中砲火']


URLを収集して → 要素の取得 → 保存 の流れ

>>> lists = sel.xpath('//*[@id="zg-ordered-list"]/li/span/div/span/a/div/text()').extract()
>>> for list in lists:
... print(list)
アマゾンの人気の本ランキング取得
